前端是可以接触到GPU的 于是也是可以使用GPU的计算能力的 对于我这种没有很深入的GPU运算了解的程序员来说 完全从底层开始怕是也不太可能 好在已经有大神把相关的内容以及封装成库了 gpu.js 于是本文的初识的意思就是就从这个库开始 首先说明 这个库其实也还在开发当中的 也没有一个很稳定的正式版 所以很多功能都是有欠缺的 但是了解个GPU计算是啥来说 绰绰有余了
因为js是单线程的 所以并不适合处理CPU密集型的程序 但是GPU是有非常高的并行线程数 所以GPU计算的基本思想就是把计算任务分拆成N多个线程任务 每个线程返回一个结果 然后吧每个线程的结果再汇总 这个基本的思路不管是哪平台上的应该都是一样的
啥是线程的概念 咱先直接看一段代码来先感受一下
1 | const gpu = new GPU(); |
每个线程都会执行这个传入的函数 具体起多少个线程有参数output决定 可以有x,y,z三个维度 上面这个例子只取了x方向上数量100个
在函数里this.thread.x可以获取到当前执行这个函数的线程x维度上的地址 如果有多个方向的话 还有类似this.thread.y和this.thread.z的
函数接受的参数为外部调用的时候传入的参数 函数返回的值为当前线程返回的值 所有线程按照各个维度上的位置 向最外面返回一个最终的数组 就是上面那个执行的效果 每个线程直接返回了线程在x维度上的位置 最终吧所有线程按照维度的顺序合并起来 如果有两个维度 最终的值就是个二维数组 同理三个维度也是
要注意的是 这个执行的函数 最终会被库转化进入到GPU中执行 所以 所有外部js的参数和函数 还有该函数里的语句语法是有限制的 具体的解决方法可以参考文档 有向内部传入数据的方法
矩阵乘法实现
说了这么多 咱来写一个实际有用的东西 矩阵相乘 C=AB 为了方便起见 A和B都是相同大小的方块矩阵
矩阵的乘法咱就不回顾了 只提一个非常关键的地方 就是关于矩阵C中 C(i,j)的值
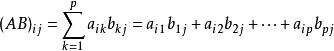
这个很关键 先吧这句翻译成程序语句
1 | let dimensions = 100; // 假设长度为100 |
于是开始写
1 | const matrixMultiplyGPU = new GPU().createKernel(function(a, b) { |
这里注意一点 线程在两个维度上的坐标顺序与结果的顺序是反的 比如线程在两个维度上是[i, j]那么在最终的结果里的位置是[j, i] 不知道这里是为啥要这样做 可能和GPU的原理有关
然后咱们随机构造矩阵 然后开始计算
1 | function createMatrix(dims, fn) { |
哈哈哈 为了方便起见 两个相同的矩阵相乘好了 拿出笔和纸 用个两三个维度的值验证了一下 发现没有问题 但是这个效率和CPU的相比 有多大的优势呢
和CPU比
然后咱们利用上面的式子写一个matrixMultiplyCPU吧 因为有上面的铺垫 所以这个就非常简单了
1 | const matrixMultiplyCPU = function(a, b) { |
验证的也很简单 直接看一下运行时间对比就可以了
1 | console.log("dimensions", dimensions) |
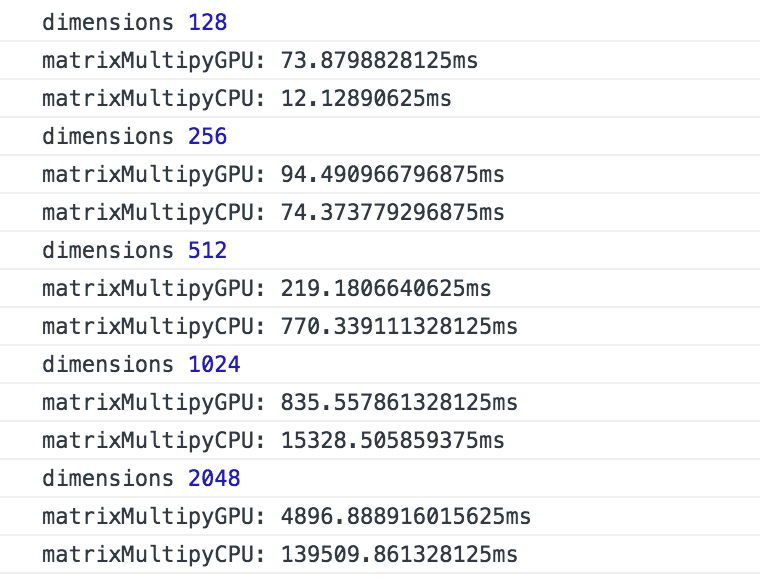
电脑配置是
- CPU - 2.6 GHz Intel Core i5
- GPU - Intel Iris 1536 MB
- Browser - Chrome Version 61.0.3163.100 (64-bit)
然后我再看下另外的结果

后面这个的配置就略高一些 所以整体的数据比上面的好一些 但是其中有个数据出了点偏差 具体啥原因也不知道 重新跑了之后结果也没大问题
- CPU - 3.2 GHz Intel Core i5-6500
- GPU - NVIDIA GeForce GTX 1060 3GB
- Browser - Chrome Version 61.0.3163.100 (64-bit)
从上面的数据来看 当矩阵维度较小的时候CPU的耗时比较短 因为当数据量少的时候 时间主要花费在将数据传输上 从内存传到显存 当数据量大了之后 计算时间开始增大 GPU才开始显现出优势
由于显存与内存本据存取上的区别 上述的代码也有非常大的优化空间 上述例子中GPU最大达到80倍的效率应该还是可以继续增加的
当然 GPU的维度也不是越大越好 实测维度过大了之后 计算还是会奔溃的 具体最佳的维度大小应该和各个GPU自己有关吧