老项目老项目了这些都是。大部分都是十年前就出现的工具。感叹真是经久不衰。
最近服务开发中,为了节约成本,弄了两个服务器,希望搭建一套数据分析平台,验证项目流程。
查了很多资料对这些平台的搭建都非常简略,过程也是复杂,对新人很不友好,我也算是整理了一下相关的内容。简化服务搭建流程。
得益于Docker的容器化,整个数据平台搭建起来非常方便
整个过程里面,包含以下工具的搭建:
- HDFS,主要是用来存储数据
- YARN,提供资源调度,实现MR计算
- Hive on MR,基于MR的SQL引擎, 性能堪忧。也有基于Spark的,但是没有找到版本对应的公共镜像,就放弃了
- Spark Standalone,分布式计算框架,有基于YARN或者HIVE的版本,为了依赖纯粹,使用了独立集群
- Kafka on Kraft,为了依赖纯粹,使用了Kraft版本,不依赖ZooKeeper
- ElasticSearch,集群版本
- Logstash,不算是数据平台组件,简单的用来把日志文件传输到kafka和hdfs,也有其他类似的工具,很多
网络
由于我们是使用多台主机,所以需要搭建一个跨主机容器之间直接可以相互访问的网络环境。
这里我们使用ipvlan l2的网络,可以实现跨主机网络访问,Docker上也可以非常简单的就可以搭建。
如果是在同一台机器上,不需跨主机相互访问,创建普通网络就可以了
创建网络
假设组件使用192.168.2.1/24网段
在需要部署组件的机器上创建网络,所有机器都需要创建这个网络。网络名称为 hostvpc,提供给后面使用。
# 创建ipvlan l2网络,跨服务器访问
docker network create -d ipvlan --subnet=192.168.1.1/16 --gateway=192.168.1.1 -o ipvlan_mode=l2 -o parent=eth0 hostvpc
# 创建普通网络,组件使用192.168.2.1/24网段
docker network create --subnet=192.168.2.1/24 --gateway=192.168.2.1 hostvpc
这个网络设计有一个问题:组件与其所在主机不能通信
网络结构图
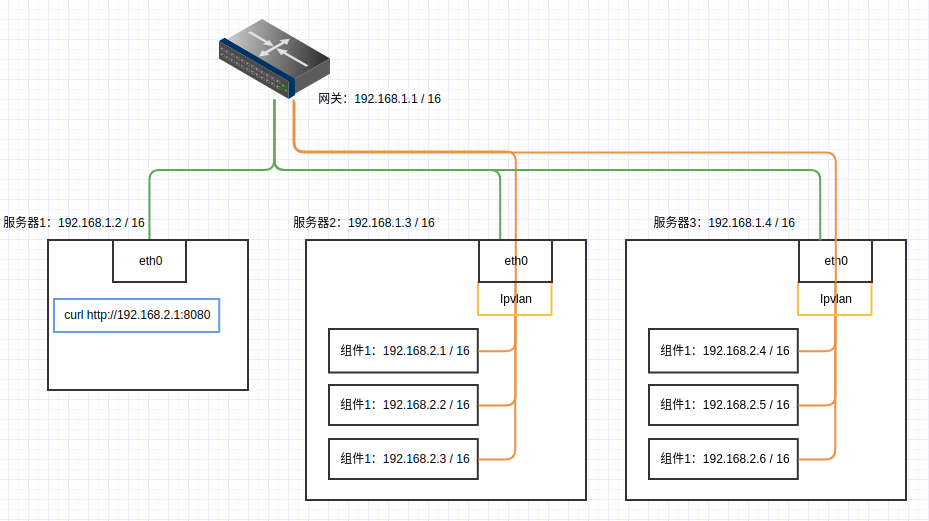
具体网段可以根据实际情况修改,组件与服务器处于同一子网即可
为了方便组件之间以及各客户端之间能方便访问,建议是在域名解析上增加对应的解析。
解析的数据 这样
# hdfs
192.168.2.10 nn.hdfs.example.com
192.168.2.11 dn01.hdfs.example.com
192.168.2.12 dn02.hdfs.example.com
192.168.2.13 dn03.hdfs.example.com
192.168.2.14 dn04.hdfs.example.com
# yarn
192.168.2.20 rm.yarn.example.com
192.168.2.21 nm01.yarn.example.com
192.168.2.22 nm02.yarn.example.com
192.168.2.23 nm03.yarn.example.com
192.168.2.24 nm04.yarn.example.com
192.168.2.29 hs.yarn.example.com
# es
192.168.2.30 kibana.example.com
192.168.2.31 es01.example.com
192.168.2.32 es02.example.com
192.168.2.33 es03.example.com
192.168.2.34 es04.example.com
# spark
192.168.2.40 master.spark.example.com
192.168.2.41 w01.spark.example.com
192.168.2.42 w02.spark.example.com
192.168.2.43 w03.spark.example.com
192.168.2.44 w04.spark.example.com
# kafka
192.168.2.51 kafka01.example.com
192.168.2.52 kafka02.example.com
192.168.2.53 kafka03.example.com
192.168.2.54 kafka04.example.com
# hive
192.168.2.60 hive2.example.com
组件
使用docker compose设置组件启动配置,组件有对应的环境变量文件。
将域名作为组件的服务名称,指定服务的ip。同一个服务器上,组件之间不需要额外域名解析也可以直接访问。单机启动的话就比较方便。
客户端连接时可以进入网络--net=hostvpc,或者指定域名解析--dns x.x.x.x,或者直接配置hosts都是可以的
需要更改域名或者ip的,组件及对应环境变量里需要自己修改
所有组件各自的配置可以查看配置源码
Hadoop-HDFS
关键组件,所有的数据存储都在这。后来也有用s3作为存储的。
配置源码hadoop-hdfs
启动命令
docker compose up -d nn.hdfs.example.com
docker compose up -d dn01.hdfs.example.com
docker compose up -d dn02.hdfs.example.com
docker compose up -d dn03.hdfs.example.com
docker compose up -d dn04.hdfs.example.com
命令测试
webhdfs地址: http://nn.hdfs.example.com:9870/
# 上传下载测试
docker run --rm -v `pwd`/data.csv:/data.csv bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8 \
hdfs dfs -fs hdfs://nn.hdfs.example.com:9000 -put /data.csv /data.csv
docker run --rm bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8 \
hdfs dfs -fs hdfs://nn.hdfs.example.com:9000 -ls /
docker run --rm bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8 \
hdfs dfs -fs hdfs://nn.hdfs.example.com:9000 -text /data.csv
Hadoop-YARN
组件本身配置复杂又多,很想替换掉,但是因为Hive on MR的依赖,不得不启动一个。后续对此有更详细的说明。
配置源码hadoop-yarn
启动命令
docker compose up -d rm.yarn.example.com
docker compose up -d nm01.yarn.example.com
docker compose up -d nm02.yarn.example.com
docker compose up -d nm03.yarn.example.com
docker compose up -d nm04.yarn.example.com
# docker compose up -d hs.yarn.example.com # 可以不启动
命令测试
任务调度历史与节点信息: http://rm.yarn.example.com:8088/cluster
启动MR计算还是比较麻烦的,因为客户端要指定一样的配置文件,yarn的配置文件也是一大堆
# 运行mapreduce计算圆周率
docker run --rm --env-file ./yarn.env \
bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8 \
hadoop jar /opt/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar pi 3 3
基于MapReduce的Hive服务
本来是想使用Spark作为Hive的计算引擎。但是Spark和Hive的版本兼容比较差,版本要一一对应。相关的公共镜像没有找到合适的版本,我又不想自己打镜像,迫于无奈,只能先上一个基于MR的版本。Yarn作为资源调度服务可以说是又臭又长,很想替换掉。
详情可以查看Hive on Spark
元数据我们存储在MySQL
本组件启动源码hive-on-mr
启动命令
- 依赖
jdbc.jar, 可以从dev.mysql.com下载 - 依赖数据库,当前组件使用外部
mysql作为hive元数据存储, 需要修改环境变量配置 - 启动组件
yarn后,可以使用hadoop-yarn的调度执行MapReduce,在docker-compose.yml可以配置导入yarn的环境变量 - 不配置
yarn环境则使用LocalJobRunner进行本地运算,在docker-compose.yml可以移除对应环境变量
# 首次启动需要初始化数据库
docker compose run hive2.example.com schematool --dbType mysql --initSchema
# 启动服务
docker compose up -d hive2.example.com
命令测试
组件信息: http://hive2.example.com:10002
关于启动命令中,中文乱码的问题,需要加上环境变量HADOOP_OPTS="-Dfile.encoding=UTF-8"
另外由于docker本身的问题,docker run命令传入带空格的参数时有一点点问题。导致beeline命令直接使用-e参数无法执行, 详情。可以使用文件传入或者使用管道输入。
# hive shell
docker run --rm -eHADOOP_OPTS="-Dfile.encoding=UTF-8" -it bde2020/hive \
beeline -n root -u 'jdbc:hive2://hive2.example.com:10000'
echo 'show databases;' | docker run --rm -eHADOOP_OPTS="-Dfile.encoding=UTF-8" -i bde2020/hive \
beeline -n root -u 'jdbc:hive2://hive2.example.com:10000'
# 可以访问hdfs
docker run --rm bde2020/hive hdfs dfs -fs hdfs://nn.hdfs.example.com:9000 -ls /
Spark独立集群
spark有很多种启动方式,例如有基于Yarn。但是为了组件纯粹性,这里使用了独立集群,不需要依赖其他服务。配置也非常简单。
提交任务的时候需要注意使用 cluster模式
启动命令
docker compose up -d master.spark.example.com
docker compose up -d w01.spark.example.com
docker compose up -d w02.spark.example.com
docker compose up -d w03.spark.example.com
docker compose up -d w04.spark.example.com
命令测试
组件信息: http://master.spark.example.com:8080/
# spark-shell
docker run --rm -it bitnami/spark:3.3 spark-shell --master spark://master.spark.example.com:7077
echo 'sc.textFile("hdfs://nn.hdfs.example.com:9000/data.csv").count()' \
| docker run --rm -i bitnami/spark:3.3 \
spark-shell --master spark://master.spark.example.com:7077
# 使用集群模式计算pi
docker run --rm bitnami/spark:3.3 \
spark-submit --master spark://master.spark.example.com:7077 --deploy-mode cluster\
--class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.3.1.jar
# 在集群外,不能使用client模式提交任务
Kraft模式的Kafka集群
kafka在原先的版本依赖ZooKeeper,被人诟病了很久,在新的版本里支持了Kafka模式的启动方式。Kafka Without ZooKeeper
为了组件的纯粹,我们也使用了这个模式, 不依赖 ZooKeeper。
启动命令
# 依赖1001用户权限
mkdir -m 777 ./volumes-kafka01 && docker compose up -d kafka01.example.com
mkdir -m 777 ./volumes-kafka02 && docker compose up -d kafka02.example.com
mkdir -m 777 ./volumes-kafka03 && docker compose up -d kafka03.example.com
mkdir -m 777 ./volumes-kafka04 && docker compose up -d kafka04.example.com
命令测试
# 获取Cluster ID
docker run --rm bitnami/kafka kafka-cluster.sh cluster-id \
--bootstrap-server "kafka01.example.com:9092,kafka02.example.com:9092,kafka03.example.com:9092,kafka04.example.com:9092"
# 消费数据
docker run --rm bitnami/kafka kafka-console-consumer.sh \
--bootstrap-server "kafka01.example.com:9092,kafka02.example.com:9092,kafka03.example.com:9092,kafka04.example.com:9092" \
--topic "datastream.test"
ES 集群
配置源码elasticsearch
有一个坑,需要对服务器设置max file descriptors,可以执行ulimit -n 65535
详情可以查看官方文档file-descriptors。
启动命令
ulimit -n 65535
mkdir -m 777 ./volumes-es01 && docker compose up -d es01.example.com
mkdir -m 777 ./volumes-es02 && docker compose up -d es02.example.com
mkdir -m 777 ./volumes-es03 && docker compose up -d es03.example.com
mkdir -m 777 ./volumes-es04 && docker compose up -d es04.example.com
docker compose up -d kibana.example.com
命令测试
Kibana页面: http://kibana.example.com:5601
# 查看集群信息
curl "http://es01.example.com:9200/"
# 查看节点信息
curl "http://es01.example.com:9200/_cat/nodes"
Logstash
配置源码logstash
本例子将日志写入kafka与hdfs,具体配置可以参考文档
虽然这个工具使用docker compose启动的,但是配置和前面的几个服务比起来似乎没那么优雅。也不做展示了